
A boon for all collaborative and iterative work, version control systems are, fundamentally, software tools which make a record of all changes made to work files in a way that you can revisit specific ‘versions’ at a later time. To truly understand why version control is necessary, however, requires a brief discussion on version history.
Version History
The concept of version history is simple: imagine starting a project on Google Drive and sharing the first draft. Everyone on the team suggests edits, members implement the changes which make the cut, new copies get made in the process and then are merged into the “main” file. Sometimes, a rollback to a previous version is necessitated and you go through the aforementioned ‘copies’ to find the right version to revert to. The cycle ends when a new version is generated. All this is done through email, Slack, or whatever tools your team uses for work communication.
Now, the idea behind version history sounds really simple but it can actually be downright messy if the team isn’t in sync, or aren’t communicating clearly, or if there are deadlines to meet (a key time when there can be breakdowns in communication).
Version Control
Whereas the focus of any version history system is on providing access to all discrete ‘versions’ of project files, version control, as its name suggests, focuses more on the control aspect. This extends to things like who is able to access which files, controlling the making and merging of branches for different tasks and seeing who made certain changes, when they were made and any associated notations.
What this boils down to is the reduction in unnecessary communication in version control systems, which helps optimize workflow for better productivity. Version control generally exists in two hierarchies: centralized version control and distributed version control.
Centralized Version Control
In a centralized version control system, there is one “central” copy of the project on a server – all changes are committed to this copy. Anyone wishing to work on the project can only pull the files they need, as the full project is not made available locally. Apache Subversion (SVN) is an example of a centralized version control system.
Distributed Version Control
In contrast, a distributed version control system does not have a central server with all project data on it. A process known as cloning is used to deposit a complete copy of the project onto a local computer, bringing along with it all project history. If this sounds familiar, that’s because this form of version control has been popularized by Git.
What Version Control Achieves
The software industry has had widespread implementation of version control, the achievements are significant and need to be examined as a sort of blueprint for the hardware product industry. Here is a quick summary:
Improvements to testing & development
Software is always under development. Companies are looking to implement new features or improve existing ones and that means that the source code is always being tinkered with in various different ways. Often, different people within the same team may be working on different development projects on the same software product, which means they are writing new source code and modifying the existing code on their own clones of the main project. They have to ensure that their code functions properly before it can be integrated into the main project – that goes for every engineer working on their individual features or improvements. Version control allows software teams to save a tremendous amount of time as different parts of a product’s source code can be developed simultaneously.
Improvements to tracking, fixing and history
With software engineers able to work simultaneously on multiple aspects of the same project, a consequence is the generation of tremendous amounts of new code which needs to be tested thoroughly before it can be implemented into the main, commercial code. Diffing, or, the ability to see exactly what changes were made and by whom, is invaluable in helping developers fix bugs and errors – or even removing erroneous code without impacting the primary project.
An additional benefit of a comprehensive history of all code versions is that it allows the team working on the project to grow or change easily, by allowing newer developers to track just how a specific part of the code evolved to its current state.
Improvements to collaborating
These improvements can primarily be attributed to distributed version control systems such as Git or Mercurial, as they permit software engineers in different geographical locations to collaborate on the same project at the same time. This is something not accessible to those utilizing centralized version control systems; in fact, real-time collaboration is one of the primary reasons distributed version control like Git gained such popularity among the software industry and community.
Hardware Development and the Lack of Version Control
Why hardware version control is different from software version control
Version control in software is relatively easy; since all code is text, diffing can be implemented merely by highlighting the changed text in project files. Things in the hardware world aren’t as cut and dried, however.
Hardware design involves creating printed circuit boards (PCB) on a variety of EDA tools (such as Altium, Cadence, 3ds Max), or developing electronic schematics. Most of these tools handle files in proprietary binary formats, which aren’t conducive to the sort of comparisons available in software differencing, while schematics and PCB diagrams are visual information that can’t be handled by the text-centric version control systems used in software development. For instance, two schematic versions may only differ by a single component such as a resistor or capacitor – identifying these small visual changes in the design files requires differencing that is specific to the needs of hardware engineers.
The inefficiencies of existing PDM
Any company utilizing CAD to create designs will invariably also have to turn to some form of Product Data Management (PDM) tool to keep their files organized and in control.
However, existing PDM tools tend to implement far more version history than version control. In a word, that means inefficiency. Instead of visual differencing, many tools rely on generating PDFs or images, and then providing some rudimentary form of comparisons that often need manual oversight to be of any use. In the process of exporting designs to PDFs, metadata gets lost, which means a lack of reusability and the loss of material specifications, among other things. This also means that communication via annotations on design changes is less than ideal, if at all possible.
What this also means is that tracing errors or bugs can be a challenging task, as it adds on a significant amount of time and cost overhead for searching for and validating a replacement part (if needed), and an unnecessary amount of back and forth communication among the team. It must be remembered that any new product uses hundreds, thousands or even more different components spread across the globe, each with their own unique usage parameters, electrical tolerances and availability in the market due to their planned obsolescence. The selection of each component requires all this information and more to be up to date – choosing the wrong component could set back design and production significantly.
The issue with adopting existing PDM for your product data and life cycle management needs is that by eschewing the advantages of version control over history, these solutions forego a collaborative and hardware process-oriented approach that would be cost-effective and accelerate commercialization. What they offer instead are incredibly expensive workflow tools with an equally high time cost for setting up and learning, with the massive caveat that these workflow optimizations only work within their own proprietary software. These are the solutions most of the industry still operates on, and by ignoring the untapped potential of version control, they continue to languish.
The industry-wide cost of not adopting version control
Poor control spans a variety of issues plaguing the industry. It refers to poor data management that results in engineers wasting a third of their time merely searching for and verifying information they need to do the real work: innovate and build. It refers to poor visibility/access and transparency of data and sharing within the industry, leaving engineers scrambling to identify design data changes in and outside collaborative environments, thus limiting the reusability of such designs in the future.
A hesitation to invest time and money into hardware version control has a very simple and ironic consequence: the time and money cost of creating a new product has skyrocketed. The time to commercialize is inexcusably long, especially when comparable industries have accelerated due to timely disruption, in particular the software industry. Innovation and new ideas have become a trickle due to the high cost of entry – testing, fixing and iterating on a new idea is a very long and costly process, which drives the hardware community away from executing upon those ideas.
Ignoring the barriers driving away new innovators, the high cost and time associated with taking a product from ideation to commercialization can be attributed to wasteful daily processes involved in creating hardware products. It’s something that companies should be looking into, as cutting down on production costs is the fastest way to increase profitability.
The Benefits of Opting for Version Control
Rapid prototyping and iteration
One of the best features of version control is the branch functionality. Attempting something new is as simple as creating a branch of your main project and continuing work as normal. If that test develops into something worth implementing into the final product, version control can easily let you merge the test branch back into the “master” project. Similarly, if the experimental prototype idea does not work out, that means the original project does not get impacted in any way.
This ease of prototyping, testing and collaborating in a version control enabled workflow means that costly bugs and errors can be reduced significantly, which is a major financial and time roadblock in many production cycles.
Granular data and privacy control
Another issue with basic version history methods is privacy. Most cloud storage facilities have improved security but that comes at the cost of making the process of sharing files and data more complicated – with most projects having a large number of working files, it adds to the time wasted in tracking down which files need to be shared with whom. With version control, you can set team and individual permissions and the software manages everything for you.
Efficient, essential communication
Project management isn’t just data and workflow management – communication is a key determinant. With the version history-based or proprietary workflow implementations of existing PDM, the communication aspect is often relegated to email or Slack. However, these apps can create roadblocks, from technology failures to team members simply not seeing their messages in time, all creating unnecessary delays.
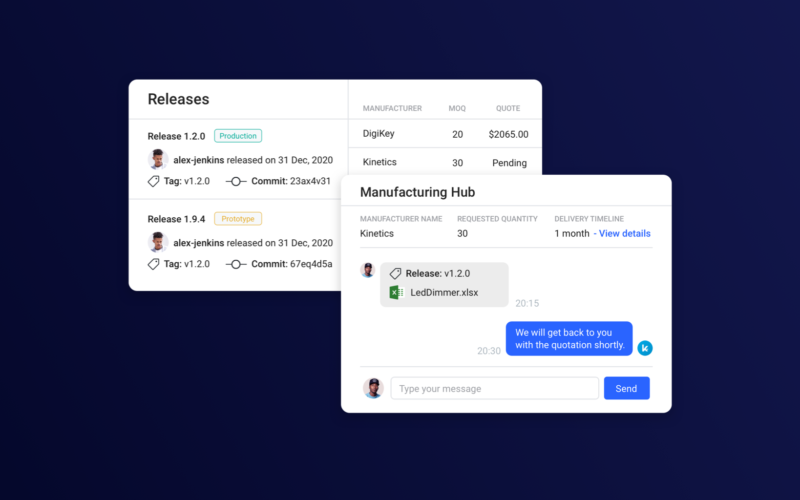
With version control, however, features like commit messages, interactive annotations, and robust notifications eliminate any such delays.
Lower time and cost of production
The benefits to hardware engineers and their everyday processes are evident. However, version control also has tangible benefits towards the bottom line as well – by eliminating redundant communication and automating non-value-added work that would otherwise account for nearly half of the work time spent by engineers, version control guarantees faster go-to-market and a general increase in the pace of design and development of electronic hardware. That means reduced production costs and ultimately, greater market success.
Summary
The reluctance to implement hardware version control is currently what stands between the industry and accelerated and cost-effective product commercialization. It’s also the reason why companies and their vital collaborative data is walled behind artificial fences created by the proprietary software currently used by the industry to manage product data and life cycle, thus stifling community innovation.
Until version control and its collaborative potential is adopted, the hardware industry will continue to waste time, money and the creative ability of the entire engineering community that drives it.